How To Interpret Semantic Tokens¶
See also
- Example Server
An example implementation of semantic tokens
- textDocument/semanticTokens
Semantic tokens in the LSP Specification
Semantic Tokens can be thought of as “Syntax Highlighting++”.
Traditional syntax highlighting is usually implemented as a large collection of regular expressions and can use the language’s grammar rules to tell the difference between say a string, variable or function.
However, regular expressions are not powerful enough to tell if
a variable is read-only
a given function is deprecated
a class is part of the language’s standard library
This is where the Semantic part of Semantic Tokens comes in.
How are tokens represented?¶
Unlike most parts of the Language Server Protocol, semantic tokens are not represented by a structured object with nicely named fields. Instead each token is represented by a sequence of 5 integers:
[0, 2, 1, 0, 3, 0, 4, 2, 1, 0, ...]
^-----------^ ^-----------^
1st token 2nd token etc.
In order to explain their meaning, it’s probably best to work with an example. Let’s consider the following code snippet:
c = sqrt(
a^2 + b^2
)
Token Position¶
The first three numbers are dedicated to encoding a token’s posisition in the document.
The first 2 integers encode the line and character offsets of the token, while the third encodes its length. The trick however, is that these offsets are relative to the position of start of the previous token.
Hover over each of the tokens below to see how their offsets are computed
- Token Line Offset Length
- c 0 0 1
- = 0 2 1
- sqrt 0 2 4
- ( 0 4 1
- a 1 2 1
- ^ 0 1 1
- 2 0 1 1
- + 0 2 1
- b 0 2 1
- ^ 0 1 1
- 2 0 1 1
- ) 1 0 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 1 | c | = | s | q | r | t | ( | ||||
| 2 | a | ^ | 2 | + | b | ^ | 2 | ||||
| 3 | ) |
Line = 1 - 1 = 0
Offset = 0 - 0 = 0
Line = 1 - 1 = 0
Offset = 2 - 0 = 2
Line = 1 - 1 = 0
Offset = 4 - 2 = 2
Line = 1 - 1 = 0
Offset = 8 - 4 = 4
Line = 2 - 1 = 1
Offset = 2 - 0 = 2
Line = 2 - 2 = 0
Offset = 3 - 2 = 1
Line = 2 - 2 = 0
Offset = 4 - 3 = 1
Line = 2 - 2 = 0
Offset = 6 - 4 = 2
Line = 2 - 2 = 0
Offset = 8 - 6 = 2
Line = 2 - 2 = 0
Offset = 9 - 8 = 1
Line = 2 - 2 = 0
Offset = 10 - 9 = 1
Line = 3 - 2 = 1
Offset = 0 - 0 = 0
Some additional notes
For the
ctoken, there was no previous token so its position is calculated relative to(0, 0)For the tokens
aand), moving to a new line resets the column offset, so it’s calculated relative to0
Token Types¶
The 4th number represents the token’s type. A type indicates if a given token represents a string, variable, function etc.
When a server declares it supports semantic tokens (as part of the initialize request) it must send the client a SemanticTokensLegend which includes a list of token types that the server will use.
Tip
See semanticTokenTypes in the specification for a list of all predefiend types.
To encode a token’s type, the 4th number should be set to the index of the corresponding type in the SemanticTokensLegend.token_types list sent to the client.
Hover over each of the tokens below to see their corresponding type
- Token Line Offset Length Type
- c 0 0 1 0
- = 0 2 1 2
- sqrt 0 2 4 3
- ( 0 4 1 2
- a 1 2 1 0
- ^ 0 1 1 2
- 2 0 1 1 1
- + 0 2 1 2
- b 0 2 1 0
- ^ 0 1 1 2
- 2 0 1 1 1
- ) 1 0 1 2
- Index Type
- 0 variable
- 1 number
- 2 operator
- 3 function
Token Modifiers¶
So far, we have only managed to re-create traditional syntax highlighting. It’s only with the 5th and final number for the token do we get to the semantic part of semantic tokens.
Tokens can have zero or more modifiers applied to them that provide additional context for a token, such as marking is as deprecated or read-only.
As with the token types above, a server must include a list of modifiers it is going to use as part of its SemanticTokensLegend.
Tip
See semanticTokenModifiers in the specification for a list of all predefiend modifiers.
However, since we can provide more than one modifier and we only have one number to do it with, the encoding cannot be as simple as the list index of the modifer(s) we wish to apply.
To quote the specification:
Since a token type can have n modifiers, multiple token modifiers can be set by using bit flags, so a tokenModifier value of 3 is first viewed as binary
0b00000011, which means[tokenModifiers[0], tokenModifiers[1]]because bits0and1are set.
Hover over each of the tokens below to see how their modifiers are computed
- Token Line Offset Length Type Modifier
- c 0 0 1 0 8
- = 0 2 1 2 0
- sqrt 0 2 4 3 5
- ( 0 4 1 2 0
- a 1 2 1 0 0
- ^ 0 1 1 2 0
- 2 0 1 1 1 0
- + 0 2 1 2 0
- b 0 2 1 0 2
- ^ 0 1 1 2 0
- 2 0 1 1 1 0
- ) 1 0 1 2 0
- Index Type
- 0 deprecated
- 1 readonly
- 2 defaultLibrary
- 3 definition
| Index | 3 | 2 | 1 | 0 |
| 2Index | 8 | 4 | 2 | 1 |
8 = 8
5 = 1 + 4
2 = 2
Finally! We have managed to construct the values we need to apply semantic tokens to the snippet of code we considered at the start
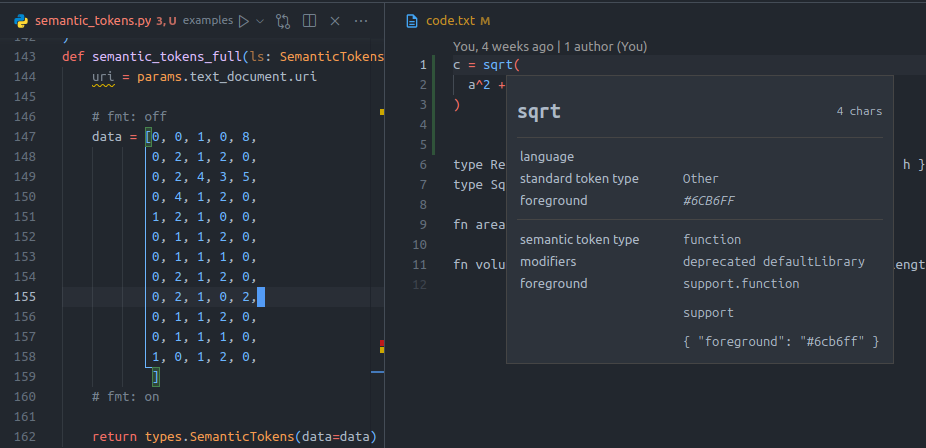
Our semantic tokens example implemented in VSCode¶